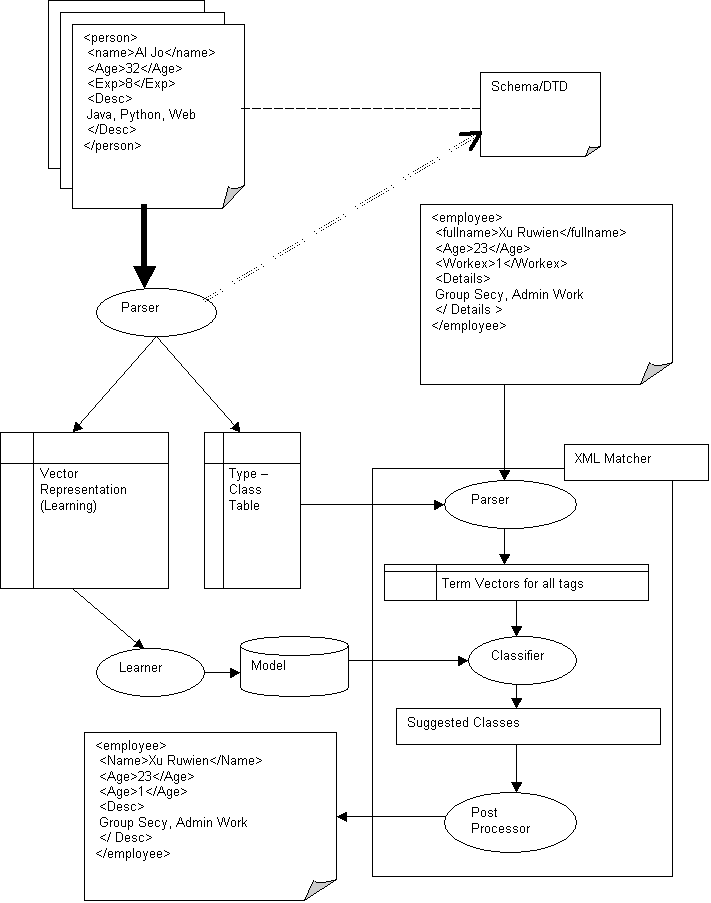
Identifying Structural Mapping between XML Fragments
Machine Learning Approach
Sub Problem
Given a XML document collection having common schema, find a new test document, find the how much does
The can be broken into two
- Learn the content types of the various tags in the documents in training set
- Given the test document, the machine, for each leaf tag tries to match the tag in training set that best matches itself.
Latest Screenshots (End of day, Nov 22)
Mappings Generated
generatorAgent( 1) +generatorAgent(1) generatorAgent
creator(16) +creator(1)+subject(15) subject
description(16) +description(14)+title(1)-description(1) description
language( 1) +language(1) language
title(16) +creator(1)+title(11)-title(4) title
item(15) +item(15) item
subject(15) +subject(15) subject
li(15) +li(15) li
channel( 1) +channel(1) channel
items( 1) +items(1) items
RDF( 1) +RDF(1) RDF
date(16) +date(16) date
Seq( 1) +Seq(1) Seq
link(16) +link(16) link
Class Total + - ~ Acc
> generatorAgent 1 1 0 0 1.0000
> creator 16 0 16 0 0.0000
> description 16 16 0 0 1.0000
> language 1 1 0 0 1.0000
> title 16 16 0 0 1.0000
> item 15 15 0 0 1.0000
> subject 15 15 0 0 1.0000
> li 15 15 0 0 1.0000
> channel 1 1 0 0 1.0000
> items 1 1 0 0 1.0000
> RDF 1 1 0 0 1.0000
> date 16 16 0 0 1.0000
> Seq 1 1 0 0 1.0000
> link 16 16 0 0 1.0000
> Overall 131 115 16 0 0.8779
Accuracy Results
> Overall 131 100 31 0 0.7634
> Overall 131 115 16 0 0.8779
> Overall 131 100 31 0 0.7634
> Overall 131 115 16 0 0.8779
> Overall 132 115 17 0 0.8712
> Overall 131 115 16 0 0.8779
Average Accuracy 0.838616666666667
Final Set of Goals (Due, Begin of Day, Nov 24)
Final set of tasks due
- Complete the previous experiments.
- Structural Information, in each node encode the following
i. Number of siblings of a node
ii. Number of siblings of parent of node
iii. Level of the tag
iv. Is children repeating
v. Is repeating
vi. Is parent repeating
- Content Information, for each leaf node encode
i. Meta attributes like term / document frequency: Min, Max & Average
- Post processing
i. In case all the suggestions are weak, instead of vote, use the suggestion with highest confidence.
ii.
If multiple tags get the
same class, and if it’s a non-repeating tag, match only if confidence is
greater than a certain thresh hold.
iii.
Check if a tag has already
matched, avoid re-matching it, unless it is repeating.
- Output options
- Accuracy result
- For each example
i. Suggested Mappings
ii. Individual Accuracies, per tag
iii. Overall Accuracy
- Graphical Mapping?
- Input Options
- Whether to do post processing. Not required
- Whether to use any of the following content information for leaf tags
i. Content itself
ii. Length
iii. Null
- Whether to use any of the following structural information for non-leaf tags
i. Num of children
ii. Num of attributes
iii. Is a tag leaf
iv. Does a tag have repeating children
- Project Report
- Format: Paper or Document?
- Demo Script
Latest Screenshots (End of day, November 16)
Test one, train on rest
bash-2.03$ grep 'Overall' results.vanilla
> Overall 131 76 38 17 0.5802
> Overall 131 82 17 32 0.6260
> Overall 131 79 28 24 0.6031
> Overall 131 83 16 32 0.6336
> Overall 105 45 23 37 0.4286
> Overall 132 93 19 20 0.7045
> Overall 131 91 20 20 0.6947
Avg 0.615496188
bash-2.03$ grep 'Overall' results.postp
> Overall 131 84 47 0 0.6412
> Overall 131 99 32 0 0.7557
> Overall 131 83 48 0 0.6336
> Overall 131 81 50 0 0.6183
> Overall 105 45 60 0 0.4286
> Overall 132 99 33 0 0.7500
> Overall 131 82 49 0 0.6260
Avg 0.6423787
Post-processing
Class Total + - ~ Acc
> generatorAgent 1 0 0 1 0.0000
> creator 16 0 15 1 0.0000
> description 16 14 1 1 0.8750
> language 1 1 0 0 1.0000
> title 16 11 0 5 0.6875
> item 15 15 0 0 1.0000
> subject 15 5 0 10 0.3333
> li 15 0 0 15 0.0000
> channel 1 1 0 0 1.0000
> items 1 1 0 0 1.0000
> RDF 1 1 0 0 1.0000
> date 16 16 0 0 1.0000
> Seq 1 1 0 0 1.0000
> link 16 16 0 0 1.0000
> Overall 131 82 16 33 0.6260
Found mixed suggestions for generatorAgent. Enforcing errorReportsTo
Found mixed suggestions for creator. Enforcing subject
Found mixed suggestions for description. Enforcing description
Found mixed suggestions for title. Enforcing title
Found mixed suggestions for subject. Enforcing subject
Found mixed suggestions for li. Enforcing title
Class Total + - ~ Acc
> generatorAgent 1 0 1 0 0.0000
> creator 16 0 16 0 0.0000
> description 16 16 0 0 1.0000
> language 1 1 0 0 1.0000
> title 16 16 0 0 1.0000
> item 15 15 0 0 1.0000
> subject 15 15 0 0 1.0000
> li 15 0 15 0 0.0000
> channel 1 1 0 0 1.0000
> items 1 1 0 0 1.0000
> RDF 1 1 0 0 1.0000
> date 16 16 0 0 1.0000
> Seq 1 1 0 0 1.0000
> link 16 16 0 0 1.0000
> Overall 131 99 32 0 0.7557
Next Set of Goals (Due: Begin of day, November 18)
- Test Setup modifications: Done
- Use of entire XML document for testing rather than an fragment
- Use existing 8 training documents as the whole set
- Use of training on 7, test on 1 analysis
- Use of accuracy figures to come up with results
i. For each document
ii. For each tag
iii. For the total set
- Structural Information
- For number of child elements, encode if it’s repeating: Done, gets good results
- For each of the elements
i. The fact if it’s a leaf element. Done
ii. Encode how many siblings it has
iii. How many siblings of parent it has
iv. The level of a tag in the tree.
- Store the fact that one tag occurs the same number of times as another tag. Though this can’t be used as a feature, it can be used as post-processing information.
- Store order of tags to make it in the post-processing
- Post Processing Task
- For repeating tags in test set, use the voting to assign the classification if all the classifications don’t match: Done, gets good results
i. In case all the suggestions are weak, instead of vote, use the suggestion with highest confidence.
- If multiple tags get the same class, and if it’s a non-repeating tag, match only if confidence is greater than a certain thresh hold.
- Check if a tag has already matched, avoid re-matching it, unless it is repeating.
- If more than certain number of leaf tags have matched, matches the non-leaf parent tag
- Add a hypothesis about post-processing. Done
Next Set of Goals (Due: Begin of day, November 11)
- The output below should have shown perfect match for all the tags because the test is conducted on an example that has been already trained.
- Either it’s a bug. It was a bug, found it, as on 12:43pm 11/4. It works great now, matching all the tags correctly for seen test set.
- Or the C-param of SVM has to be relaxed, to accommodate training errors
- Next set of experiments would include testing on an example that is unseen even in terms of content
- This would require training on a larger set, because things like author names would have to be learnt well. Results [heading, url, posting & date] match while category & author get mapped to ‘title’
- Perform tests with vector attributes like length as the only features (and not including words as features in the vectors)
- More vector attributes to be tested
- Type based attributes like ‘date’, ‘number’
- Meta attributes like term / document frequency: Min, Max & Average
- Use of tri-grams for content
- State the following hypothesis, predict its results & explain how can the experiments be conducted.
- Basic XML Map finding using content
- Use of vector attributes as features to improve results.
- The basic hypotheses are presented here.
- Pending Improvements / Bug Fixes
- Eliminate non-leaf tags from learning / classifying cycle.
- Structural features
- Use number of children & attributes to indicate structure
- Use [child{n}] k number of times, while [child{n-1}] & [child{n+1}] d number of times.
- Results visible: log gets
mapped to title, but has a positive mapping to ‘item’ (the correct
mapping)
- But URL starts getting mapped to title, though it has a +ve mapping to link
- Java had to be configured to run with minimum memory size of 256 MB
Latest Screenshots (End of day, November 10)
Poetry
------
log channel_()
heading title()
url title(,link,date)
posting description()
category title()
author title()
time date()
Meinem Leben
------------
log channel_()
heading title()
url link()
posting description()
category subject()
author subject()
time date()
Poetry with Structural Information
----------------------------------
log title(,item)
heading title()
url title(,link,date)
posting description()
category title()
author title()
time date()
Meinem Leben with Structural Information
----------------------------------------
log title(,item)
heading title()
url link()
posting description()
category subject()
author subject()
time date()
Latest Screenshots (Begin of day, November 4)
Training Sample
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:sy="http://purl.org/rss/1.0/modules/syndication/"
xmlns:admin="http://webns.net/mvcb/"
xmlns:cc="http://web.resource.org/cc/"
xmlns="http://purl.org/rss/1.0/">
<item rdf:about="http://weblogs.cs.cornell.edu/aseem/archives/000312.html">
<title>Lucky Dog</title>
<link>http://weblogs.cs.cornell.edu/aseem/archives/000312.html</link>
<description>1 pm in the after noon you get a job from Lehman Brothers on Wall Street 3 pm in the Microsoft interview, you do well(not to mention the wireless keyboard you won in the raffle) 12 midnight,...</description>
<dc:subject>Updates</dc:subject>
<dc:creator>Aseem Bajaj</dc:creator>
<dc:date>2003-10-29T12:45:20-05:00</dc:date>
</item>
</rdf:RDF>
Query Fragment
<log about="http://weblogs.cs.cornell.edu/aseem/archives/000312.html">
<heading>Lucky Dog</heading>
<url>http://weblogs.cs.cornell.edu/aseem/archives/000312.html</url>
<posting>1 pm in the after noon you get a job from Lehman Brothers on Wall Street 3 pm in the Microsoft interview, you do well (not to mention the wireless keyboard you won in the raffle) 12 midnight,...</posting>
<category>Updates</category>
<author>Aseem Bajaj</author>
<time>2003-10-29T12:45:20-05:00</time>
</log>
Output Generated
log RDF()
heading title()
url link()
posting description()
category date()
author description(,link)
time description()
(the colors above indicating errors in results are not a part of the output, but have been manually done)
Issues to be discussed (Begin of day, November 4)
- Vector length has been encoded & implemented. The results improved marginally.
- Term Weights: How to make term weights heavy for parameters like ‘vector length’ in the vector
- Tokenization: Fields that have composite values like ‘2003-10-29T12:45:20-05:00’ can’t ever match with something like ‘October 29, 2003’.
- Lemur doesn’t have options for various tokenizations
- Should we handle tokenization before indexer in Lemur?
- Should the above example be encoded like ‘##has_number##’ or should it be ‘##date##’ alone? The issues with former is that even general fields would have ‘##has_number##’ in them, though that approach is more easy to implement.
- Data Types: Should be just go by data types?
- Each tag would have a set of properties like ‘##text##’, ‘##large##’, ‘##has_number##’
- The greater the match of properties, the closeness to data type, the better the similarity.
- If only the data type is considered, we would mix up ‘Title’, ‘Category’ and ‘Author’, but would certainly separate it from description. Besides would work really well for URL and date.
- If content were also considered, unseen authors, categories etc, would have a remote fuzzy match.
Analysis & tasks scheduled for the week
- Post processing
- While predicting the data type of a tag, choose a prediction only if the classification predicted is positive. Avoid choosing the best prediction if it’s negative.
- Need to figure out when there are two similar tags in the XML, which ones it chooses.
- Use of text length as another attribute. The length can be encoded like ##3## for a length, it can also choose attributes in ranges, like for lengths 0-10, uses ##ten## for others ##greater##
Update Logs (End of Day, October 24)
- Wednesday, figured out that Orange for Python is not a good idea because even though it mentioned about a sparse vector input file format called Basket, but it had no documentation of how to import it. Couldn’t figure that out.
- Wednesday, found jSVM, a wrapper over SVMlight by Berkeley people. They have modified SVMlight code. Compiles and works on Solaris.
- Thursday, wrote the code for parsing RSS 1.0 feed in XML format. Generated Lemur indexer based input, performed the complete machine learning and classification loop.
- Leaning using 30 Blog entries in RSS 1.0 format. Each entry had 6 tags.
- 1 classification. Didn’t parse this new format, but hand coded the Lemur index format.
- Results not good, only one of the tags classified right.
- Thursday, started work on integrating XML Parsing code & JSVM code. Tried to compile jSVM on Windows. SVMlight bundled with jSVM didn’t compile
- Friday, tried compiling SVMLight original on windows, and it did work. Tried compiling SVM light bundled with jSVM didn’t work again. Gave up on it
- Friday, decided to move everything to Solaris
- Friday, setup the project directory and build program. Compiled & tested the XML parse script on Solaris, it worked. Tried jSVM test program for learning and classifying data, it worked.
- A paper on finding the Semantic Mapping between tags of two XML document [PDF]
Comparison with Text Classification
We are classifying content in tags here rather than the documents themselves. It’s a multi class single label problem.
Terms & Definitions
Tags and nodes are used interchangeably here.
Classes
Each tag name in a given document is a class. Given a new test data, each of its leaf tags would be judged by its content type.
Training & Test sets
For each leaf node in the training documents, each tag with content is a class & the content a value.
Vector Space Representation
The content of a given tag in all the n documents is used to form n training vectors for that class.
Tokenization
Unresolved issue: Tokenization of data oriented fields is significantly different from content oriented field and that is quite possible in typical xml semi-data, semi-content documents. For example the content
Feature Selection
Words are used as features.
Results
For each of the tags in the training set that best matches each of the leaf tags in the test document, identify a mapping between the two XML structures.
System Design
List of Classes
|
Id |
Type |
Tag |
|
|
|
|
|
1 |
Name |
<name/> |
|
2 |
Age |
<age/>, <exp/> |
|
3 |
Desc |
<desc/> |
Vector Representation
|
Class |
|
|
|
|
|
|
|
|
Name |
1:0.5 |
2:0.5 |
|
|
|
|
|
|
Name |
23:0.7 |
53:0.1 |
1293:0.3 |
|
|
|
|
|
. |
|
|
|
|
|
|
|
|
. |
|
|
|
|
|
|
|
|
Desc |
21:0.11 |
43:0.68 |
213:0.11 |
729:0.1 |
|
|
|
|
Desc |
8:0.1 |
8679:0.1 |
1221:0.1 |
230:0.1 |
2167:0.1 |
836:0.5 |
|
Process