
|
The Internet Archive Research Group |
Background
The Internet Archive is building a digital library of Internet sites and other cultural artifacts in digital form. The collections currently include books, movies, concerts and web sites. From the beginning, the Internet Archive has called upon researchers to mine the collections both for scholarly purposes regarding historical content and to find ways to improve the accessibility of information in the Archive. Various scholars have been involved in mining the web collection, but until this Fall little work had been done on highlighting interesting content to the website's users.
This past summer Jon Aizen began working with the Internet Archive to transform their previously static website into a true digital library, complete with catalog, search, review, discussion capabilities and dynamically updated statistics for items. The Archive was expanded to include books, some software, and concerts, as well as doubling the size of the movies collection.
Jon's research with Jon Kleinberg and Dan Huttenlocher began in the Fall of 2002. The two professors had visited the Internet Archive in San Francisco and were familiar with the website and the organization's ideals.
User Download Behavior and Engagement Research
Our research began with a focus on the behavior of users when visiting details pages. It quickly became apparent there exist patterns of behavior exhibited by users at these pages. We began by first examining the amount of time users spend at a given item's details page, with particular regard to their decisions of whether or not to download an item. We started by trying to plot this information visually and ended up with graphs like this one:
Makes a lot of sense, right? Well, we knew what the graphs were trying to say, but had to constantly remind overselves. "So what does it mean if a details page is in this corner?" was our question, over and over again. Here is an annotated version of the graph (each red dot is a details page):
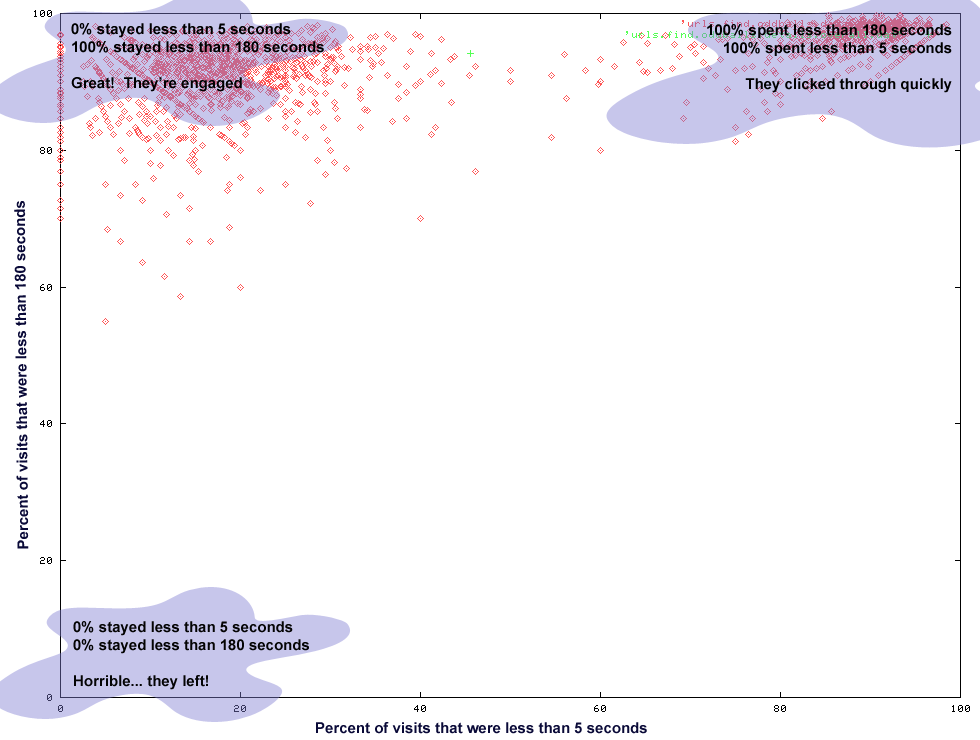
Unfortunately, we never really made this annotation automatic, so we constantly had to remind ourselves. But we soon found a better solution which took the form of text based visualizations:
details--TO--movie.downloads (18%) ---------|-----------------------------------------
-------------------X----------------------------------------------------------------------------X----
19 96
The above example provided us with a visual representation of the following information: 18% of users who visited a details page, continued on to download a movie. Of those 18% that actually proceeded to download the movie, 19% spent less than or equal to 5 seconds on the details page, 77% spent between 6 and 180 seconds at the details page, and 4% spent more than 180 seconds on the details page (which we took to be an indication of lack of interest). We fiddled with the 5 and 180 second values, terming this the engagement window. Analyzing the statistics across all the pages, we found that users were engaged when they spent between 8 and 45 seconds on a given page. This period of time was long enough to not be a "click through" to another page, yet short enough to suggest that the user didn't get up to get a cup of coffee. Here are some additional examples (all from September 28th, using 5 and 180 seconds as the boundaries):
details-audio--TO--downloads (30%) ---------------|-----------------------------------
---------------------------------X----------------------------------------------------------------X--
33 98
details-texts--TO--downloads (23%) ------------|--------------------------------------
----------------------------X----------------------------------------------------------------------X-
28 99
Batting Averages
These graphs proved pretty interesting to stare at, but presented little information that would be of relevance to the users of the website. We were looking for something that could provide some useful information to users about the specific interest of a given item. This led us to the notion of (what we would soon call) engaged batting averages. Every item could be given an EBA computed by: number of visits to the item's details page where the visit duration was in some range (15 to 75 seconds was one range used) divided by the total number of visits to the item's details page.
As it turned out, the engaged batting averages were less informative than a simpler notion which we called download batting averages (or just batting averages). Analogous to batting averages in baseball (the number of hits divided by the times at bat of a particular player), download batting averages are computed by dividing the number of downloads (coming from the item's details page) by the number of visits to the item's details page. We looked at lists such as this one from November 6th, a sample of which is provided here:
We soon realized that these figures would be of interest to users. Specifically, we thought that ranked content boxes of items sorted by batting averages would be more useful than the previous (highly visible) standard of ranking items by number of downloads. Ranking items by number of downloads makes "the rich get richer" by ensuring that the most downloaded items will remain the most downloaded items (because they are the most visible). Because the batting averages are affected by visits as well as downloads, they change much more frequently (in fact, one click to an item's details page can remove an item from the top five!). Furthermore batting averages can be very high for items that have been viewed by very few users (so long as the majority of those few users actually downloaded the item). This feature of batting averages was extremely exciting to us because it provided a way to highlight information that might otherwise remain burried in the Archive. In late November we incorporated ranked batting average lists into the live website. However, before doing so we felt like we need to correct items with relatively few downloads. It just didn't sit right with us to rank an item with 5 downloads out of 10 visits (and hence a batting average of 50%) higher than an item with 490 downloads out of 1,000 visits (batting average of 49%). Yet, at the same time, we still wanted to highlight items that hadn't been viewed that much. To do this we entered an adjusment to the formula, making the computation of batting averages equal to [(# of downloads) / (# of visists)] - (1.1/sqrt(# of visits)). The resulting "normalized" batting averages we initially captured in this list, a sample of which follows:
Progressive Batting Averages
As we developed the notion of batting averages and examined the figures for different pages, both before and after the incorporation on the live website, we became interested in the way batting averages change over time, and the forces which might influence these highly volatile figures. We started by examining progressive batting averages, a snapshot of an item's batting average at each visit in the item's history. The resulting graphs looked like this:

Looking at progressive batting averages proved interesting and worked to enhance our understanding of batting averages. In particular, these graphs lead to an experiment where we determined the average number of visits before an item's batting average stablized.
Sliding Windows
Moving on, we wanted to look at batting averages over sliding windows. The notion was fairly simple: during visit i through i+x, plot the batting average. We graphed these windows for all values of i between 1 and the number of visits per page. The motivation behind this concept was to visually isolate windows of time when the batting average was changing dramatically. We got pretty interesting results:

We were highly optimistic about the rises and the drops until we realized that random data looks strikingly similar. Nevertheless, we decided to plot the appearance of reviews in these graphs to see if such an event might describe a major change in an item's batting average. We felt that the appearance of a review (which consequently pushed the item into the spotlight by making a temporary link on the main page and the collection landing page in the "recently updated reviews" content box) was likely to greatly reduce an item's batting average by driving a lot of traffic to the item (and therefore increasing the denominator in the batting averages equation). The resulting graphs looked like the following example (green lines represent reviews, and the height of the green line denotes the number of the stars associated with the review):

Since, as mentioned earlier, the rises and drops were also present in random data which we plotted, we decided to devise a method of the impact of each review. We came up with a number for each review which we termed review sigmas. The number essentially represented how different the batting average for the item was during some period after the appearance of the review. This number was calculated as the number of standard deviations away from the overall mean batting average. The resulting graphs were interesting but not much more informative:

Finally, we wanted to make one more change to the graphs. Until this point the X values were spaced equally for each visit, regardless of the time between visits (so essentially the X-axis represented visit number, not time of visit, although we did label the axis with visit time to be a little informative). As mentioned earlier, the sliding windows were based on number of visits, not a duration of time. So one window (with z visits) might have spanned three weeks and then another window for the same details page (also with z visits) might have spanned three days, depending on traffic to the page. Using an algorithm devised by Jon K., we changed this notion of sliding windows based on visits to sliding windows based on fixed time. We proceeded to plot graphs with a sliding window of one week. The results were a lot easier to conceptualize. Compare the following graph to the one directly about this paragraph to see the difference.

At this point we were ready to start doing some experiments to really determine the impact of the reviews on the batting average of an item. All our work thus far had been to just get a sense of how we might go about measuring impact and the above graphs were certainly a catalyst for this thought process. From the beginning we had wanted to find a way to use Jon K.'s recent work with burst analysis, and it seemed like we had found the perfect application...
Burst Analysis
Inspired by Jon Kleinberg's work on burst analysis (Bursty and Hierarchical Structure in Streams. Proc 8th ACM SIGKDD Intl. Conf. on Knowledge Discovery and Data Mining, 2002: PS and PDF). From Jon's page: "the high-level idea is to analyze a stream of documents and find features whose behavior is `bursty': they occur with high intensity over a limited period of time." When applied to user behavior on the Internet Archive website, we can think of bursty activity as periods of very many or few visits to a given details page. The idea is that if we can identify bursts of activity for a given details page, then the events that caused these bursts are very likely to be interesting. We've started to do burst analysis compared with the appearance of reviews. This research is still in the first steps, but an example graph looks like this:

The above graph depicts the hidden state (which correspondings to batting average) at each visit to the details page of an item. Issues with the above graph, such as the massive, short period, drops in state are currently being dealt with. In particular, Dan's recent work on improving the performance of the dyanmic programming algorithm which generates this state transition information has been crucial in making this work possible with a large numver of states (we are currently using 80 states, a number only feasible with a linear time algorithm).
Our goal is to eventually, using the burst analysis information, come up with numbers representing the long and short term impacts of each review of an item. This could potentially allow us to automatically "rate" a review on the website, telling users that the review did or did not influence user download behavior. This is a particuarly novel concept which is of great excitement to us.
Batting Averages Comparison
At the end of the semester we implemented a feature on the website which allows us to track where users are coming to details pages from (more accurately than simply using referers, this feature allows to know what part of a refering page the user clicked on to get to the details page). Appropriately, we've been calling this specific information an item's "from" variable. Out of interest we decided to see which "froms" are more likely to result in a download at the details page and the resulting data and graphs were very interesting. We began by examining the batting average for each item for each "from." Some sample results from early February can be accessed here. We then made graphs for the sake of visual comparison.

For each value of "from", f, we made a graph like the one above. The green bars are "froms", y, which, when a user came to a details page from y resulted in lower batting averages than when users came from f. The opposite holds for the bars. A full list of graphs is available here.
In particular, this research revealed several interesting facts:
Rank Histories
At the same time that we generation the information described above we also performed a short experiment (the results are available here) on the number of hours an item appears in the top 5 items (ranked by batting average) for its corresponding collection and for its corresponding mediatype. This is of particular interest because when an item has one of the top five batting averages, it appears in the "Top Batting Averages" content box on its collection landing page and on its mediatype landing page. This results in very high visibility for the item.
One item that was of paritcular interest is a movie called A Visit to Santa in the Prelinger Archives collection. This item was "spotlighted" during Christmas time, which means that a staff member picked it to be featured in the spotlight content box on the Prelinger landing page and on the movies landing page. The result was a dramatic increase in the items batting average and pushed it into the top 5 for both mediatype and collection. When the holidays passed the item lost steam and was replaced by a different film. The graph of these changes is provided here:

Batting Averages Visibility Experiment
Finally, one of our most recent experiments (still in progress) concerns the visibility of batting averages. On every details page the batting average for that item appears above the links to download the item. We were curious what impact, if any, displaying the batting average there has on likelihood of downloading the item. So we decided to randomly show the batting average to half of the users and to hide it from the other half. The results (which dynamically update with every click to a details page or download) are available at the Archive: http://www.archive.org/~jon/onoff.php. Preliminary results suggest that the difference between batting averages when the figure is displayed versus when it is not are quite negligible. Nevertheless, the experiments provides the framework for future trials on what features of the details page are likely to induce downloads.
Future Research
This summer Jon A. will be graduating and leaving to work full-time with the Internet Archive. Dan and the two Jons plan to continue working together in the future, both through telelcommunication and in person during down-times in school and work. The Archive is committed to providing access to the website for researchers and finding new and productive means for interacting with scholars and researchers.
If you're interested in conducting research with the Archive, one well-established program is research access to the Wayback Machine collection (terrabytes of archived web pages dating back to 1996. Researchers are given accounts on Internet Archive servers, with access to a vast array of powerful tools (such as p2, a particularly interesting piece of code written by Andy Jewel, which allows users to perform tasks in parallel across many machines with one command).
Researchers
Jon Aizen - joa4@cornell.edu
Cornell Computer Science Major (2003)
Internet Archive Web Engineer
Antal Novak - afn2@cornell.edu
Cornell Computer Science Major (2003)
Jon Kleinberg - kleinber@cs.cornell.edu
Cornell Computer Science Professor
Daniel Huttenlocher - dph@cs.cornell.edu
Cornell Computer Science Professor
Terms and Definitions
Details pages: At the Internet Archive every item (except for archived web pages) has its own "details page." Similar to details pages at Amazon, these serve as the source of all information for a given item. The details pages contain recent reviews and ratings, download counts, links to download the item, descriptions, release dates, synopses, keywords, categories, and other information. For example, here are some links to details pages:
Content boxes: Each mediatype and collection landing page on the website is composed of content boxes featuring lists of items, most of which are sorted by some criteria. These lists include the most downloaded items, the most frequently accessed categories, items related to this day in history, and items with the highest download batting averages. When a content box appears on a mediatype landing page, the list is composed of items from all the collections belonging to that mediatype. Naturally, when a content box appears on a landing page for a collection, the items are exclusively items from that collection.
Landing pages: Every mediatype in the Archive (audio, texts, moving images, and software) has its own page. This page is termed a landing page because it is where users "land" when they click on a link in the navigation bar. Additionally, each mediatype is composed of different collections (except for software and audio which each only have one collection). Each of these collections has its own landing page as well. The landing pages for collections show information and navigational links only for items and categories in that collection. On the other hand, the landing pages for mediatypes include information and links for all items of that mediatype. The following are some examples of landing pages:
Reviews: Every item in the Archive can be reviewed by a registered user. Users are required to give items a star rating between 1 and 5. When an item is reviewed (or when a review is updated), it appears on lists of recently updated reviews. One of these lists exists on the main page of the website and another such list exists on the collection landing page of collection to which the item belongs.
Links