


Determine what kinds of specialized metadata you need to have associated with your web resources.

The best way to come up with new metadata elements is to consider the breadth of questions you would like the agent to be able to answer.



To support cross domain resource discovery, it is good practice to include the Dublin Core metadata elements when tagging a resource.

Here is the XML metadata used in this prototype:
<?xml
version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:cuinfo="http://www.cornell.edu/metadata/cuinfo">
<rdf:Description rdf:about=http://>
<dc:identifier>http://people.cornell.edu/pages/ajf15/b</dc:identifier>
<dc:title>
Leveraging Metadata for Natural Language Processing
BOOM 2002
</dc:title>
<dc:subject>
<rdf:Bag>
<cuinfo:subject>Artificial Intelligence</cuinfo:subject>
<cuinfo:keywords>BOOM 2002, BOOM,
Artificial Intelligence,
Metadata, Dublin Core, Semantic Indexing, Natural Language
Processing, AIML, Chatbots</cuinfo:keywords>
</rdf:Bag>
<dc:subject>
<dc:description>
This project uses XML metadata to improve searching
accuracy in the form of an interactive chatbot that is both
significantly more intelligent than a pure text search, and
provides a more natural user experience.
</dc:description>
<dc:coverage>
<rdf:Bag>
<cuinfo:campuslocation>Upson 315</cuinfo:campuslocation>
<cuinfo:audience>All</cuinfo:audience>
</rdf:Bag>
</dc:coverage>
<dc:creator>
<rdf:Bag>
<cuinfo:contact>Alex Faaborg</cuinfo:contact>
<cuinfo:email>ajf5@cornell.edu</cuinfo:email>
</rdf:Bag>
</dc:creator>
<dc:publisher>
<cuinfo:department>Computer Science</cuinfo:department>
</dc:publisher>
</rdf:Description>


After deciding on which elements to use, you need to register every piece of content. The metadata itself can be stored in a database, or can reside in XML in the web pages, which will be routinely harvested by a web spider.

or
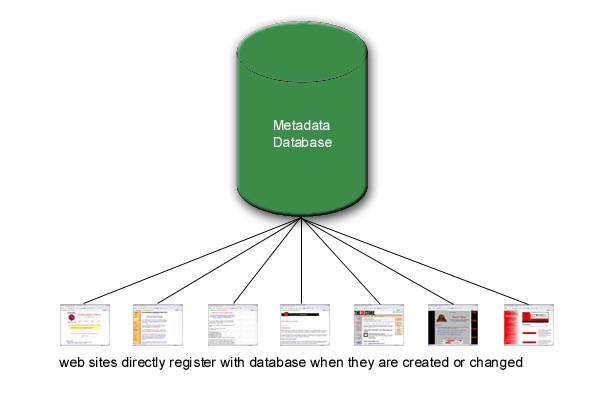
The actual creation of the metadata is usually done by humans, although if the tags are easily derived from the content, the registration process can be automated.


The NLP Engine acts as a layer between the way humans ask questions and a database query on the metadata.
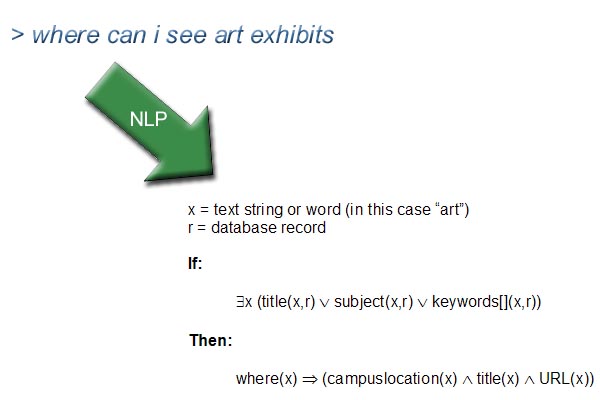
This prototype uses a very simple open source NLP Engine created by the ALICE AI foundation. I wrote a program that takes the XML metadata for each resource and generates thousands of sentences with wild card segments that can be triggered by the user.
<category>
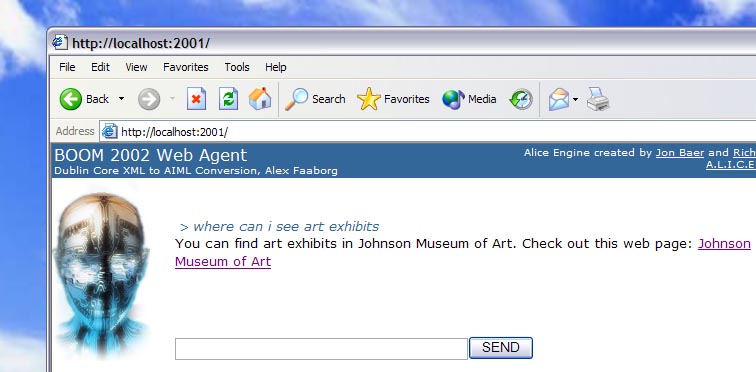
<pattern> WHERE * ART EXHIBITS</pattern>
<template>You can find art exhibits in Johnson Museum
of Art.</template>
</category>


The user interface in the prototype responds to questions with links to relevant web pages or email addresses. This is a faster and more natural experience compared to browsing for specific information on CUinfo.
Next, learn about what Tim Berners-Lee believes is the future of the Internet, the Semantic Web
